Nachdem ich mich in meinem Beitrag „Was ist anders bei agiler Planung“ mit den grundlegenden Mechanismen agiler Planung beschäftigt habe, stellte Maximilian Scherf die Frage, „Wie kann ich denn so beurteilen zu welchem Zeitpunkt ich was fertig haben werde?“ Die Frage ist sehr berechtigt, aber nicht so einfach zu beantworten, so dass ich hier in einem eigenen Eintrag darauf antworten möchte – zumindest grob.
Grundsätzlich muss man sich darüber im klaren sein, dass eine Terminaussage in einem Softwareprojekt die Vorhersage eines chaotischen Systems ist und damit der Wettervorhersage ähnelt (ich rede hier von chaotischen Systemen im Sinne der Theorie komplexer Systeme, nicht aus der Perspektive von Eltern, die in das Kinderzimmer schauen). Chaotische Systeme zeichnen sich dadurch aus, dass ihr Verhalten umso schwerer vorhersagbar ist, je weiter man in die Zukunft schaut: Die Wettervorhersage für die nächsten fünf Minuten bekommt auch der Laie üblicherweise korrekt hin, für den nächsten Tag müssen selbst Profis erheblichen Aufwand treiben und für mehr als eine Woche sind seriöse Vorhersagen derzeit nicht möglich.
Im Projektmanagement sind die planbaren Zeithorizonte zum Glück deutlich länger: Eine Woche ist meist kein Problem, einen Monat bekommt man auch noch ganz gut hin, ab einem Quartal wird es eng. Eine „genaue“ Vorhersage ist daher unmöglich, bei einer „verbindlichen“ Zusage muss man schon relativ vorsichtig sein, was man unter welchen Voraussetzungen verspricht. Erlaubt ein Planungsverfahren nur digitale Aussagen darüber, was „geschafft wird“, ist es also unrealistisch und nur wenig brauchbar. Statt dessen braucht man ein Verfahren, das einem zumindest ungefähre Aussagen zur Wahrscheinlichkeit ermöglicht: „So wie dieses Feature derzeit priorisiert ist, wird es mit 80% Wahrscheinlichkeit im nächsten Release enthalten sein“. Genügen einem diese 80% nicht, muss man es eben höher priorisieren – auf Kosten anderer Features, die dadurch weniger wahrscheinlich werden.
Wie kommt man auf Basis agiler Planung zu einer solchen Aussage? Die Basis sind die Schätzungen und die Erfahrungswerte aus den vorigen Iterationen. Die Grafik unten stammt von einem meiner Kunden, also aus einem real existierenden Projekt. In ihr sieht man die aus der Häufigkeitsverteilung abgeleitete Wahrscheinlichkeit, dass innerhalb einer Iteration mindestens n Aufwandspunkte abgeschlossen werden. Man kann aus dieser Kurve zum Beispiel ablesen, dass in mehr als 50% der Fälle mindestens 21 Punkte abgeschlossen wurden, in mehr als 80% der Fälle mindestens 13 Punkte und so weiter. Mit anderen Worten: Ist eine Aufgabe so hoch priorisiert, dass ihr eigener geschätzter Aufwand und der aller höher priorisierten Aufgaben in Summe weniger als 13 Punkte ausmacht, so wird sie in dieser Iteration mit mindestens 80% abgeschlossen werden. Oder noch anders formuliert: Ich kann Aufgaben für bis zu dreizehn Punkte Aufwand für diese Iteration zusagen, wenn mir 80% Erfüllungswahrscheinlichkeit ausreichen. Brauche ich 90%, sollte ich mich auf 10 Punkte beschränken, mit (fast) 100% erreiche ich 8 Punkte und reichen mir 50% so kann ich munter 21 Punkte „versprechen“. Unabhängig von dem, was man versprochen hat, zeigt diese Grafik aber auch, dass man sich auch für den Fall rüsten sollte, dass man deutlich mehr schafft, also ruhig für 42 Punkte Features aufnehmen, auch wenn man ziemlich sicher weiß, dass man das kaum erreichen wird (Die Grafik stammt übrigens aus meinem Vortrag für die OOP 2009).
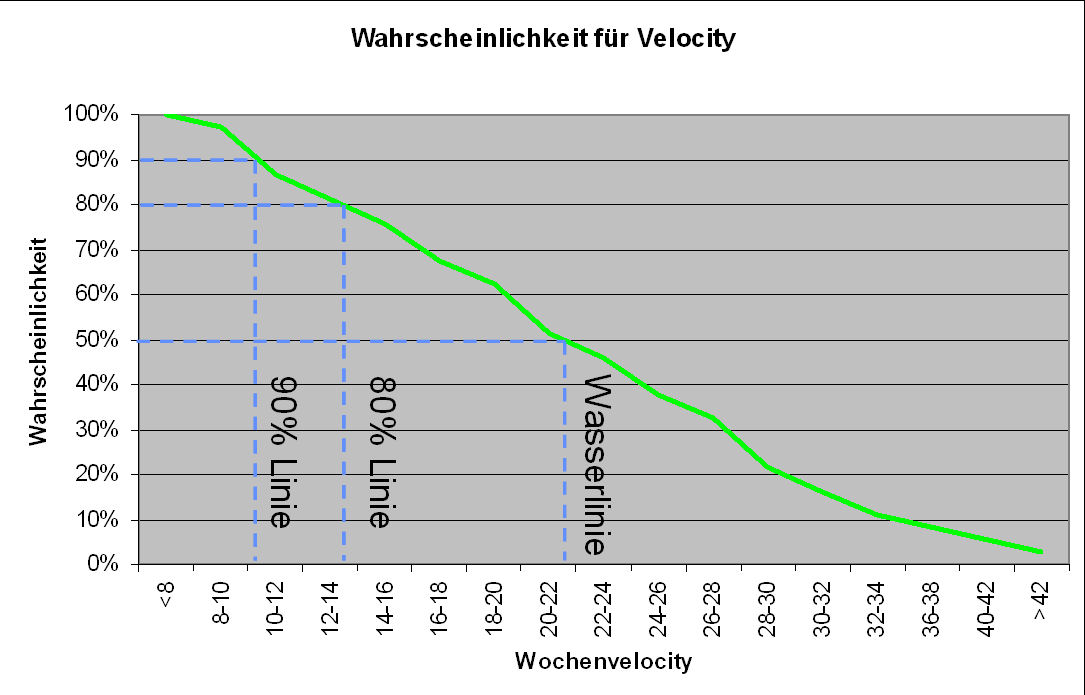
Kann ich für eine gegebene Aufgabe sagen, mit welcher Wahrscheinlichkeit sie innerhalb der nächsten Iteration fertig wird, so kann ich daraus auch längerfristige Vorhersagen ableiten, allerdings erstmal nur unter der — reichlich unrealistischen — Annahme, dass sich die Priorisierung in der Zwischenzeit nicht ändert. In der Regel ist das aber schon mehr als ausreichend, um zum Beispiel den Umfang des nächsten Releases kommunizieren zu können, ohne sich hinterher zu blamieren.
Für längerfristige Vorhersagen wird aber auch eine solche wahrscheinlichkeitsbasierte Technik zu unrealistisch. Hier kann man wieder Anleihen in der Meteorologie nehmen, diesmal in der Klimavorhersage. Dort wird nicht mit einem Modell gearbeitet, sondern es werden verschiedene Szenarien unter verschiedenen Annahmen berechnet, aus denen sich ein Korridor ergibt. Aber das würde jetzt den Umfang eines Blogeintrags endgültig sprengen.
Aufmerksame Leser werden jetzt anmerken, dass ich Maximilian Scherfs Frage eigentlich gar nicht beantwortet habe: Mit diesen Techniken kann man nämlich erstmal nur Vorhersagen darüber treffen, welche Features ich zu einem gegebenen Zeitpunkt wahrscheinlich fertig haben werde, nicht aber, wann ein gegebenes Feature fertig sein wird. Auch wenn der Unterschied subtil ist (und in den meisten Kontexten ohne Bedeutung), reflektiert das eine Grundidee iterativer Entwicklung: Die Termine stehen fest, gedreht wird am Umfang.
Das ist zwar unbequemer, als das übliche „Termine und Umfang stehen fest“, aber dafür erspart man sich das ebenfalls übliche Drehen an der Qualität, um die Zusage einzuhalten. Schlechte Qualität ist schließlich ein Selbst- und Fremdbetrug, der für alle Beteiligten sehr teuer ist. Zwar kann man auch bei agiler Planung darauf bestehen, dass bestimmte Features zu bestimmten Terminen fertig sind, aber eben nicht mehr, als erfahrungsgemäß realistisch sind. Also in unserem Beispiel für nicht mehr als 8 Punkte pro Iteration. Das ist zwar nicht immer bequem für die Verantwortlichen, aber realistisch. Und Management auf Basis unrealistischer Annahmen sollte angesichts der derzeit in der Weltwirtschaft zu besichtigenden Folgen nur noch von wenigen mit „durchsetzungstarkem Management“ verwechselt werden und damit verdienter Maßen und endgültig wieder aus der Mode kommen.

") „Zu agilen Planverfahren ist eigentlich schon alles gesagt“ meinte Stefan Roock kürzlich auf der Eröffnung der XP Days und nur wer in den vorderen Reihen saß, konnte das ironische Blitzen in seinen Augen sehen. In der Tat stelle ich in Workshops und Diskussionen immer wieder fest, dass den wenigsten die volle Bandbreite agiler Planung bewusst ist. Viele wissen noch, wie man Planungen robust macht gegen Schätzfehler und unvorhergesehene Ereignisse und manch einer beherrscht auch noch selbst-adaptierende Schätzverfahren. Aber Techniken zur langfristigen Vorhersage oder Aussagen zur Wahrscheinlichkeit, dass bestimmte Planungspunkte auch wirklich abgeschlossen werden, sind weithin unbekannt. Dabei erlaubt der Werkzeugkasten agiler Planung nicht nur recht zuverlässige kurzfristige Vorhersagen, sondern bietet bis hin zur Entwicklung neuer Geschäftsmodelle vielfältige Möglichkeiten.
„Zu agilen Planverfahren ist eigentlich schon alles gesagt“ meinte Stefan Roock kürzlich auf der Eröffnung der XP Days und nur wer in den vorderen Reihen saß, konnte das ironische Blitzen in seinen Augen sehen. In der Tat stelle ich in Workshops und Diskussionen immer wieder fest, dass den wenigsten die volle Bandbreite agiler Planung bewusst ist. Viele wissen noch, wie man Planungen robust macht gegen Schätzfehler und unvorhergesehene Ereignisse und manch einer beherrscht auch noch selbst-adaptierende Schätzverfahren. Aber Techniken zur langfristigen Vorhersage oder Aussagen zur Wahrscheinlichkeit, dass bestimmte Planungspunkte auch wirklich abgeschlossen werden, sind weithin unbekannt. Dabei erlaubt der Werkzeugkasten agiler Planung nicht nur recht zuverlässige kurzfristige Vorhersagen, sondern bietet bis hin zur Entwicklung neuer Geschäftsmodelle vielfältige Möglichkeiten.